Dies ist eine Geschichte darüber, wie ag das Beste für Volltext-Regex-Suche in Bash auf Linux-Computern und -Servern über die Befehlszeile ist.
Verwenden Sie grep für Regex-Dateisuchen oder zum Pipen der Standardausgabe mit Regex in Bash? Während fzf und grep praktisch sind, ist ag noch praktischer.
Früher wurden bei der Regex-Textsuche in bash Befehle wie find . -type f | xargs grep “$1” verwendet, aber mit ag ist solcher Aufwand nicht nötig.
sudo apt-get install silversearcher-ag
ggreer/the_silver_searcher: A code-searching tool similar to ack, but faster.
Was ist so toll an ag
- Super schnell
- PCRE-Regex, sodass Sie positive Lookahead und mehr verwenden können
- Japanische Unterstützung
- Zeilen werden ausgegeben. Spalten können auch ausgegeben werden. ... --column
- Durchdachte Funktionen wie Hervorhebung von Suchbegriffen. Natürlich ist auch eine stille Ausgabe möglich.
- Kann Zeilen davor und danach ausgeben ... -C [int] (persönlich mein Favorit)
Ich liebe es, logisch Notizen zu machen, und habe mehrere eigene Notationen über Markdown hinaus erstellt. Wie werden Texte, die nach solchen Notationen geschrieben sind, geparst und durchsucht? Die Antwort sind reguläre Ausdrücke.
Meine Notizdateien sind zwischen /mnt/c/google_drive/note/ und /mnt/c/note/ aufgeteilt. Hauptsächlich der erstere. Darüber hinaus sind sie in everything_note.md, tmp.md, trash.md usw. unterteilt. Ich habe vielleicht in einem anderen Artikel darüber geschrieben.
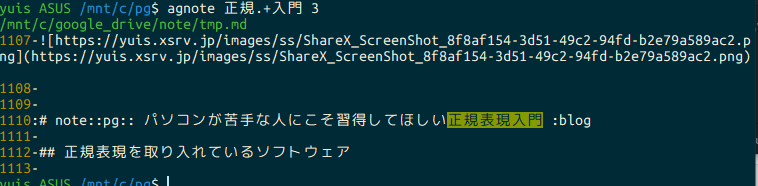
Vor diesem Hintergrund ist hier die Implementierung eines Befehls zum Durchsuchen von Textdateien in diesen Ordnern:
agnote ()
{
ARG2=${2:-0};
ag -G "^.*\.(md|txt)$" -C ${ARG2} -S "${1}" /mnt/c/google_drive/note/ /mnt/c/note/
}
-G … Datei nach Übereinstimmung einschränken -C … Kontext; Zeilen vor und nach jeder Übereinstimmung drucken -S … intelligente Groß-/Kleinschreibung (Standard)
Das zweite Argument gibt die Anzahl der Zeilen vor und nach der Ausgabe an. Das erste Argument ist das zu suchende Regex. Der Rest ist wie gezeigt.
Als Anwendungsbeispiel hier eines:
note-getskd(){
ag -G "^.*\.(md|txt)$" -C "3" -S "\s:(skd|schedule):($(date +%Y)\/)?($(date +%-m/%-d '--date=+0 day')|$(date +%-m/%-d '--date=+1 day')|$(date +%-m/%-d '--date=+2 day')|$(date +%-m/%-d '--date=+3 day')|$(date +%-m/%-d '--date=+4 day')|$(date +%-m/%-d '--date=+5 day')|$(date +%-m/%-d '--date=+6 day'))[?]?(T[0-9]{1,2}:[0-9]{1,2})?[?]?" /mnt/c/google_drive/note/ /mnt/c/note/
}Was dies tut, ist das Suchen nach zeitplanbezogenen Notizen in den Notizdateien.
Ich definiere eine durch # in Markdown getrennte Einheit als Notiz oder Notizblock, und zum Beispiel wären die folgenden zwei Notizen zeitplanbezogene Notizen:
# note::Praktische Fahrstunde :skd:5/22T13:00-
...
# note::Rücksendungsabholung :skd:3/15T13:00
...: wird als Tag definiert, und ich habe derzeit etwa 30 davon. :skd ist ein Alias für :schedule. Im Hash-Format :[key]:[value] oder :[key] sind mehrere durch Leerzeichen getrennt. Dies kann auch bei Regex-Suchen in Atom verwendet werden.
Was note-getskd tut, ist die Ausgabe von zeitplanbezogenen Notizen innerhalb von 7 Tagen ab dem heutigen Datum. Es wird mit einigen Metaprogrammierungselementen etwas kompliziert. Es hätte vielleicht bessere Wege gegeben, dies zu tun.
(Verwenden Sie einfach Google Kalender, oder? Ich bevorzuge es, alles an einem Ort zu haben.)
Irgendwie wurde die Notizen-Übersicht länger als die ag-Erklärung. Ich würde gerne eine vollständige Erklärung meiner Notizen-Methode als Serie oder Buch veröffentlichen, wenn ich die Zeit finde.